
В этой статье я расскажу о том, как был подготовлен датасет и обучена ML-модель на основе коллекции зимней одежды известного бренда. Мы сравним результаты работы моделей базовой SDXL 1.0 и её же дообученной, используя набор данных из нашей коллекции одежды, чтобы выявить преимущества и недостатки каждого подхода.
Подготовка датасета
Для обучения моделей мы собрали датасет из 42 предметов одежды. Каждая модель представлена в количестве от 2 до 8 изображений, где демонстрируется либо полный силуэт модели, либо значительная его часть. Все изображения ориентированы на отображение моделей спереди или с небольшим углом, что позволяет захватить важные детали, необходимые для тренировки ML-модели.
Изображения были подготовлены в вертикальном формате с разрешением 768×1344 пикселей. Хотя стандартный размер для генерации — 1024×1024, в данном случае вертикальная ориентация изображений является предпочтительной.

К каждому изображению прилагается текстовый файл с детальным описанием содержимого. Мы добавили артикулы каждой модели, чтобы обученная модель могла с большей точностью воспроизводить нужные элементы одежды. Для дополнительных экспериментов добавлен тег #vatoko, который может быть использован для создания общего стиля коллекции при генерации.
Поскольку для модели SDXL предпочтительны более краткие, теговые описания, мы использовали их в качестве основы. Модель FLUX, напротив, работает лучше с более детализированными контекстными описаниями, но для чистоты эксперимента мы оставили датасет одинаковым для обеих моделей.
Итоговый датасет содержит 200 изображений с соответствующими текстовыми описаниями.

Тренировка модели SDXL
Обучение модели SDXL на основе собранного датасета с использованием следующих параметров:
Epoch — 20
Num Repeats — 1
Steps — 2000
Train Batch Size — 4
Unet LR — 0.00050
Text Encoder LR — 0.00005
LR Scheduler — cosine_with_restarts
Network Dim — 32
Network Alpha — 16
Optimizer — Adafactor
Результаты
После завершения обучения мы провели несколько тестов, чтобы сравнить результат работы стандартной и обученной модели.






Мы видим, что обученная модель создает изображения на однородном фоне, как в датасете, Прически у девушек стали собранные, а модели одежды приобрели оттенок коллекции.
А теперь мы попробуем одеть девушку в одинаковой позе в разную одежду и также сравним результаты. Сперва сделаем на базовой модели SDXL.
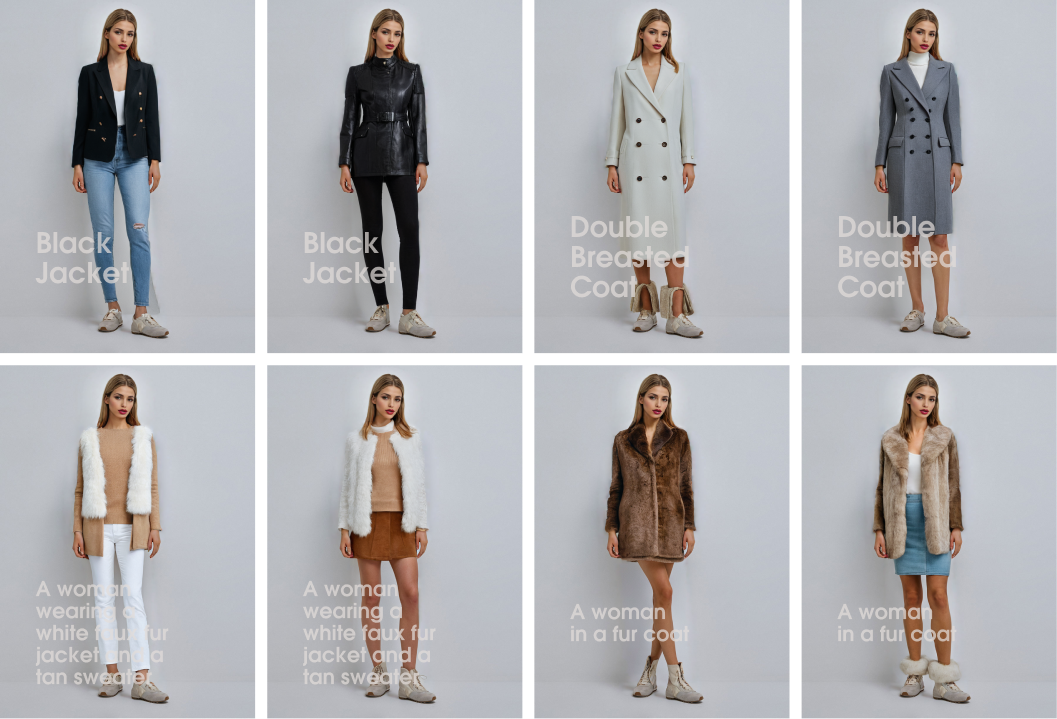
Первые тесты показали, что даже базовая версия модели неплохо справляется с генерацией одежды по заданному текстовому описанию. Однако были замечены следующие недостатки: модели часто создают узкие брюки или приталенные пальто, а также пропускают элементы, например, голые ноги, которые не соответствуют зимней тематике коллекции.
Для дальнейших тестов мы использовали ту же текстовую команду, но теперь применили нашу обученную модель, адаптированную под стиль коллекции зимней одежды.

Результаты показали значительное улучшение. Генерации стали ближе к заданному стилю: брюки стали шире, пальто более объемные и менее приталенные, что соответствует духу коллекции. Даже без явного указания зимних элементов в запросах, модель автоматически подбирала свободные фасоны, характерные для зимней одежды. Также заметно улучшилось соответствие общей цветовой гаммы.
Выводы.
Эксперименты показали, что обученная модель SDXL успешно запоминает фон и стабильно выдает изображения с однородным задним планом. Лица моделей также стали более консистентными, и их черты зачастую повторяются, создавая узнаваемый стиль.
Однако стоит отметить, что, несмотря на улучшения, модель пока не способна детально воспроизвести артикулы одежды. Это может быть связано с недостаточным количеством повторений при обучении, а также с наличием большого разнообразия моделей в датасете.
Для дальнейшего улучшения результатов можно увеличить количество повторений при обучении, а также провести тесты на модели FLUX, которая может предложить другой подход к генерации изображений, основанный на контекстных описаниях.
Заключение
Технологии машинного обучения продолжают открывать новые возможности для модной индустрии, позволяя создавать и редактировать образы с высоким уровнем детализации и стилистической точности. Обучение моделей на конкретных датасетах помогает лучше понимать специфику коллекций и адаптировать результаты генераций под конкретные запросы.
Следующим шагом в нашем исследовании станет обучение более сложных моделей и увеличение количества тренировочных шагов для достижения еще более точных результатов. Оставайтесь с нами — впереди много интересного!



